
There is still room for discarding the waiting part of beam racing and only keeping the “workaround for buggy drivers with bad vsync” part. But this is now different than the original proposal.
OK, I now see what you mean, but the good news is it doesn’t negetate different advantages of beam racing:
Even if you eliminate beam raced input reads, you can still combine the two by only worrying about retroactive inputread insertions (no beamraced input read updates). In this sense, beamracing simply only becomes another form of VSYNC ON mode.
There are still two other advantages:
(1) Immediate refreshing of delivered pixels. It’s another mode of next-frame-response that bypasses driver’s VSYNC ON delays. (Yes, there are other ways to get next-frame input response, but having an additional method is useful!).
(2) It eliminates the need to surge-execute the final frame, lessening CPU horsepower.
So even if we indeed lose beamraced input reads (whenever in RunAhead mode), we still have the other beamracing benefits (1) and (2).
Metaphorically, we treat beamracing as an in-house VSYNC ON mode with no further inputreading. So this keeps symmetry between VSYNC ON and the beamraced frameslice mode. Perhaps this makes beamracing less useful when combined with RunAhead, but they are not incompatible for other advantages.
Both beam racing and RunAhead should be concurrent options that can be enabled separately at least but they could/should still be compatible with each other (even if you are right and we indeed lose beamraced input reads; focussing only on retroactive input reads). Beam racing works on an old GTX 380 from year 2009 (640x480, output to arcade CRT, no filters/HLSL/fuzzylines renderers), and also works on a Raspberry Pi (4K versions) so it is a CPU-reducing method, as long as the GPU bandwidth is sufficient to do high VSYNC OFF pagefliprate of redundant framebuffers… There are situations where beam racing works on systems that aren’t RunAhead-capable because the CPU is not powerful enough to run emulator 2X faster. So it’s useful to have both options available.
So, if we do that, we might as well make both of them compatible with each other (e.g. via the raster callback API I suggested). Isn’t that the logical move, anyway?  Even if we have to disable the specific on-the-fly inputreading feature during beamracing (only have it do cached inputreads from beginning of cycle, just exactly like for VSYNC ON – pretending our beamracing is simply our own roll-our-own VSYNC ON driver, only for the specific use-case of concurrent use with RunAhead). Obviously, for non-RunAhead use cases, we’d enable beamraced input reads.
Even if we have to disable the specific on-the-fly inputreading feature during beamracing (only have it do cached inputreads from beginning of cycle, just exactly like for VSYNC ON – pretending our beamracing is simply our own roll-our-own VSYNC ON driver, only for the specific use-case of concurrent use with RunAhead). Obviously, for non-RunAhead use cases, we’d enable beamraced input reads.
Two more beamracing caveats…
- Not compatible with Freesync/Gsync
- Not compatible with screen rotation or flipping.
We made beam racing compatible with FreeSync/GSYNC in WinUAE. I taught Tony Willen how to do it, and it worked perfectly! We use FreeSync+VSYNC OFF as well as GSYNC+VSYNC OFF. The First Present() begins the refresh cycle and the subsequent Present() beamraces new frameslices into that VRR refresh cycle. It does mean fast execution for fast scanouts (e.g. 2.4x faster emulator execution during a 1/144sec scanout).
The way VRR beamracing with a hybrid “GSYNC+VSYNC OFF” mode works is:
- Present() while the monitor is idling, immediately begins a new manually-begun refresh cycle. (Monitor actually waits for Present() before scanning)
- Present() while the monitor is busy refreshing, behaves as VSYNC OFF (interrupts currently scanning-out refresh cycle)
For a 144Hz VRR display, if you decide to use the platform raster API (if you beamrace VRR) then the RasterStatus.ScanLine (and ilk) also increments at the velocity of a 144Hz refresh cycle, no matter what the framerate is – even if you trigger the starts of a new refresh cycle. The monitor idles in “.INVBlank = true” as VRR is simply a variable-size blanking interval. So if the monitor is idling, that means the first Present() immediately turns “.InVBlank = true” into “.INVBlank = false” and .ScanLine begins incrementing almost instantly (Within microseconds). Yep, you the programmer, have control over starting the refresh cycles on a VRR display! That’s how VRR works – the display begins scanning immediately upon Present().
For screen rotation: We simply disable beamracing in screen rotation when the scanout direction diverges between realraster/emuraster. (It’s important to just compare scan direction: Sideways monitors with sideways arcade CRTs means left-to-right beamracing can work). There’s an API to check screen rotation on both PC and Mac. Android and probably Linux too. Also, the native orientation is nearly always top-bottom even on phones (except for a few odd phones like HTC OnePlus 5 which had the jelly effect reports, due to its reverse scan).
There is nothing preventing enable/disable beamracing on the fly. So it can automatically switch in/out of beamracing everytime a tablet is rotated away from its native scan direction. Want me to (offline) write up a proposed raster callback API and general guidelines? And vet it past a few developers?
Recommended Workflow
- Check monitor rotation is equal between real & emu -> If unequal, present full frames instead
- Check if VSYNC OFF is acceessible -> If no access to tearlines, present full frames instead
- Check if VRR is enabled --> If enabled, slight change to workflow to trigger refresh cycles with first frameslice
With an optimized beamracing workflow, I get:
- 60fps on 144Hz GSYNC = perfect smooth beamrace (requires 2.4x exec speed)
- 60fps on 240Hz FreeSync = perfect smooth beamrace (requires 4x exec speed)
- 50fps on 100Hz fixed-Hz = perfect smooth beamrace (requires 2x exec speed, beamrace 1 out of 2 refresh cycles)
It is also possible to get:
- 60fps on 75Hz = stuttery beamrace (beamrace cherrypicked 60 out of 75 refresh cycles)
Here’s a diagrammetric version. These are the existing BlurBusters-format “filmreel theme” scanout graphs, with modifications to indicate how Present() triggers refresh cycles.
If you Present() 100 times a second at exact intervals, you’ve manually created 100Hz of software-timed refresh cycles.
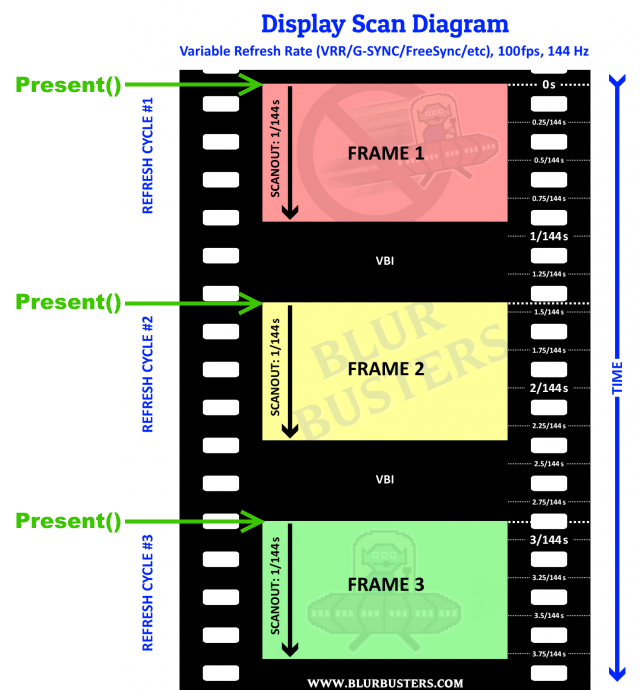
- If in VBI, Present() starts scanning a new refresh cycle (VRR behavior).
- If scanning, Present() interrupts with new frame (VSYNC OFF tearline) if using the hybrid GSYNC+VSYNC OFF mode or the FreeSync+VSYNC OFF mode.
- The first row of pixels underneath the tearline is on the video cable within microseconds of Present(), same situation as non-VRR.
Same for Mantle/OGL/etc applicable presentation APIs such as glutSwapBuffers()
That’s why we succeeded in beamracing with GSYNC in WinUAE.
Is it safe to assume 2 frames runahead would work correctly for all SNES games? I just tested it out on Donkey Kong Country 3 and it feels pretty snappy like NES 8bit which is awesome. I did another quick SloMo recording with my phone and confirmed it shaved off more than 1.5 frames very nice 
I had to enable threaded video for my Celeron N3160 to handle 2 frames of runahead flawlessly (running the Windows 32bit version using Wine on GalliumOS 64bit). I can’t tell with sub-frame accuracy from my 120fps recording but assume it would be pretty much the 2 full frames if running with threaded video disabled.
May I suggest it would be more user friendly if it could also have an automatic setting in addition to setting a manual number of frames, if you could just set runahead frames to “Auto” instead of 1, 2, 3… So it would automatically use 1 frame for the NES cores and 2 frames for the SNES cores for example, if that is known to work without any issues?
Auto would not be optimally tweaked for every game, yet, but as an easy to use “set it and forget it” option to get going. It might be possible to have this optimized per game but for now it could be set per core to begin with. It could also use a database of known and tested games and if the game has been tested simply set runahead to match, otherwise run without, so it will automatically be able to adjust more games as time goes on and the database grows with this info available…
Next, I tried out Super Mario 3 with Nestopia however that did not go so perfectly for me the sound is chopping. I increased the latency from 48ms which I used without problems before to 64ms and also tried 128ms. It seems this core is not yet handling this properly and changing the audio latency made no difference at all. Nestopia is already very low latency even without this though.
Either way something’s wrong here, framerate seems OK but the sound is not (I’m using OpenAL if that makes any difference). I didn’t enable the new statistics overlay but maybe I have some obvious problem with performance, or is Nestopia less optimized or it’s just not patched for this? The core still runs normally without runahead.
Speaking of user friendly menu options and audio performance… How about having just 48, 96, 192 kHz output rates to choose from? Then it only takes a couple of presses to go to from 48000 to 192000 for example. Well, at least the menu goes in 100Hz steps as it is already, still it’s faster to edit the config file externally than using the GUI to change that option
I’m using Nearest resampling and 192kHz rate having desktop composition (“compton” in my case) turned off so this Chromebook can run Snes9x flawlessly. With threaded video enabled it also handles 2 frames runahead, didn’t think I’d be able to get away with any runahead for SNES on this system but performance is perfect, great work!
mdrejhon, how does it behave on dos games on 60hz screen with beamracing? A lot of them are 70fps.
2 frames isn’t safe for SNES, many games have just 1 frame of lag.
The best way to be sure of how many frames of run ahead to use if you’re not sure is to pause with P and advance the frame with K while holding down an action button. Super Mario World has 2 frames of lag while Donkey Kong Country and F-Zero have 1 frame of lag.
Nestopia is compatible with run ahead. You need to make sure that “run ahead second instance” is on when using it with Nestopia or the audio will render the game unplayable.
Beam racing is mainly recommended for refresh rates higher than frame rates. Beamracing 60fps on 75Hz would be cherrypicking 60 refreshcycles out of 75 to beamrace. It’d be just as stuttery as VSYNC ON if you do that.
To do it in a forgiving way, “programming it in a way to round-off the beamrace-begins to the nearest refresh cycle and then beam racing that” would prevent a beamracing failures. If, for whatever reason, the user stubbornly kept their display at an odd refresh rate. It would click naturally for things like 60fps@120Hz, but would roundoff to the nearest VSYNCs for the odd Hz situation.
Now… Beamracing 70fps on 60Hz could theoretically be achieved by cherrypicking 60 refreshcycles and offscreen/framedropping 10 of them. But you’d have to surge-execute 10 of them, or you’d have to use a intermediate rolling frameslice queue (which creates a minor input-lag slewing artifact, but still less bad than some existing surge-execution input-lag-slew artifacts in today’s emulators when running VSYNC ON 60fps@odd Hz). I wouldn’t bother with such complexity though.
I say just make it beamrace VRR compatible and bedonewithit, to cover fps>Hz situations, and if an opensource programmer want to tweak it to be compatible with fps<Hz situation, let them. One can self-detect beam fallbehinds (failures to keep up) and switch to “surge execute the whole frame” approach to catch up. So beamracing can be selectively ignored on the fly even when beamracing is enabled in a situation that is suddenly incompatible (screen got rotated, screen lowered in Hz, screen went into windowed mode, etc).
Note: Temporary beamrace fails simply manifest itself as brief reappearance of VSYNC OFF tearing until the tearlines instantly roll back inside the jittermargins (whereupon the tearlines instantly disappear the next refresh cycle). Jittermargins can be wraparound full refresh cycle minus one frameslice, if you’re writing new emulated scanlines into into the existing emulator frame buffer containing previous emulator refresh cycle. So flipping that to the front buffer creates no tearlines as long as it’s within a (16.7ms time period minus time period of one frameslice). Even if you Present() the top part of the next emulator refresh cycle while the previous refresh cycle is scanning out, so tearline does not show because the bottom part of buffer is the previous emulator refresh cycle. (That’s why emulator modules ideally SHOULD NOT clear their emulator framebuffers between emulated refresh cycles – that’s not preservationist-proper and makes it incompatible with huge-jitter-margin capability during beam racing). For 60Hz situation, here’s an example. For 10 frameslices per cycle (1.6ms), that’s a ~15ms jitter margin for beam racing before tearlines accidentally appear – meaning beamracing has to fall behind by roughlyto enroach tearlines into a previous refresh cycle, or be too far ahead to enroach tearlines into a next refresh cycle. The amplitude of the jittermargin is 15ms in this particular case, which can make it extremely forgiving on slower systems including Raspberry Pi and Android devices if you adjust the beamrace margins as such. Emulator can execute in its own merry way (even cycle exact emulators) at realtime with no surge execution needed. The proposed raster callback API such as retro_set_raster_poll uses identical arguments as retro_set_video_refresh to allow a central beamracer module to have earlypeeks at the existing partial framebuffer and (only for supported emulator modules, and only if agreed) is explained here but I’ll formalize a better proposal in a separate thread, it may actually only require a 5 line modification to the most easily-supported emulator modules – most of the complexity is hidden in the core beamracing module.
1 Like
Is there any drawback to using “runahead second instance” in some cases ? If not, maybe it should not even be an option and always be enabled ?
It uses more resources like memory and CPU. I can’t use second instance with BSNES like I need to because it causes the emulator to drop frames like crazy and then causes save state jumping so I have to use SNES9X when I want to use run ahead for Super Nintendo. It’s something that you should only use on emulators that need it like Nestopia which has massive audio problems if you don’t use it.
Same experience with bsnes. There are so many glitches during gameplay. Frames are jumping forward and backward.
Depends on the game. Some games only need 1 frame, some need 4.
Hmm good to know! I’ll check with the pause + frame advance method to find out the value for each game.
Still have the audio problem in Super Mario 3 with Nestopia though, not only on the Windows 32bit build running on my Chromebook, but I also quickly tested it on my Shield Android TV now and it’s the same problem there. It handles crt-royale shader at full speed with Nestopia and Snes9x as long as threaded video is enabled (the Shield has multiple times the GPU performance compared to the Chromebook integrated Intel GPU).
So two very different systems with the same audio issue on both. No framerate drops, both devices run stable and smooth. Second instance option on or off, and runahead 1 frame, audio is not working properly with Nestopia in Mario 3. Did anyone else try this?
I have no idea what’s going on with the Bsnes cores, they do get out of sync (release buttons randomly) when using the secondary core. The Mednafen BSNES core is fine however.
I only experienced issues with tha graphics (frame jumping). I had to activate the second instance to get rid of the button release issue. By the way mgba also has issues. The sprites are disappearing and reappearing. Also in mgba some future frames will be displayed randomly.
The 1.7.2 release is great and the latency option is awesom. However some cores have to be optimized to work with that option flawlessly.
Actually it seems that the frame issues while using second instance on BSNES cores has been fixed in the stable release of 1.7.2. I couldn’t run it when using one of the nightly releases before the official version of 1.7.2. But now it seems to work just fine. However I still have problems with any BSNES core crashing Retro Arch when I go to close the emulator. But that’s a separate issue.
EDIT: Never mind. It got much better but BSNES still has save state warping.
I still have issues with bsnes. The frames are skipping and the input is wrong, independet of the second instance. I opened a bug: https://github.com/libretro/beetle-bsnes-libretro/issues/30#issue-319312429
Now we have the question of how to balance Smoothness, Maintaining the original frame rate, and Input Lag.
For smoothness, you want to have Vsynced frames of course. This could either be done via actual vysnc, or by the proposed beamraced vsync option.
However, using Vsync does not mean you will match the original framerate. Example, SNES runs at 60.0985 FPS, which is not 60FPS. In order to get the SNES framerate to run in the same amount of time at 60FPS, you need to drop a frame about once every 10 seconds.
Then back to Input Lag. In order to be able to drop frames, you need to gradually accumulate a buffered frame over time, and this would gradually increase input lag to one extra frame right before the point where the frame is dropped.
There is a workaround to help match the original framerate on Windows: Custom Refresh Rates on Windows. However, this requires a reboot between each change of a custom refresh rate, so if you want play SNES games (60.098 FPS), then play Genesis games (59.923 FPS), your refresh rate won’t be correct for that system.
When the original frame rate is very far from the monitor refresh rate (50FPS on 60Hz screen), then everything pretty much goes out the window, and you are forced to do full buffering, and all the extra lag that entails.
2 Likes