
The input lag chain is a very complex topic.
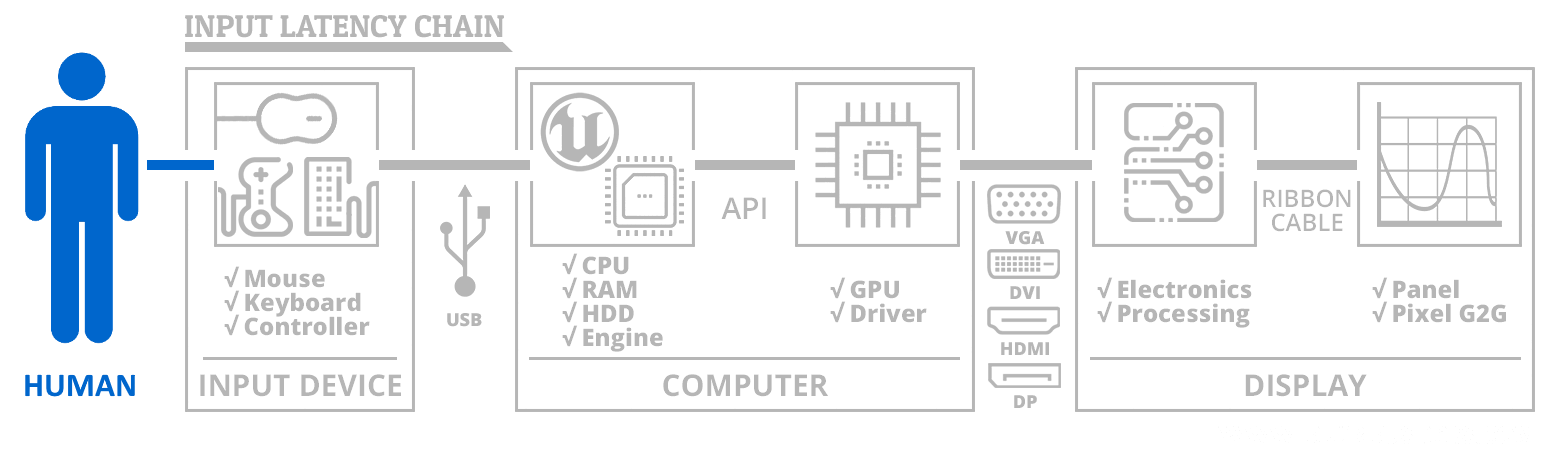
To simplify, lets focus only on emulator thru graphics output.
Traditionally, an unoptimized emulator on unoptimized drivers can:
Consider whether emulator does preemptive real input reads before renderin emulator frame, or does inout reads in realtime while doing the render (simulated raster scanout)
- Render emulator frame (varies, up to 1/60sec lag, depending on how intensive it is, and if this jiffy is executed or not to speed up individual emulator rendered frame for delivery sooner. Input read can be early in emulator frame, versus late in emulator frame)
- Deliver to graphics card (varies, up to 1 frame lag) - Present() blocks until room in frame queue. Thats buffer backpressure lag!
- Any frame queues used in the graphics card (varies, 0, or 1 or 2 frame lag). Graphics drivers delivers through any prerendered frames in sequence as consecutive individual refresh cycles.
You can make it efficient and tight (1 frame lag) but in reality, can be awful. Some very old Blur Busters input lag tests of Battlefield 4 had over 60ms input lag even on a display that had less than 10ms input lag, and even when a frame rendered in only 15ms. Conversely, CS:GO reliably achieved approximately 20ms or so. That was tests way back almost five years ago. The huge variances between software even for VSYNC ON, OFF, GSYNC… Software plays a role on how much lag they add and how they treat the sync workflows (that’s why you hear various tricks such as “input delaying” to reduce lag closer to output.)
Usually maximum prerendered frames is 1, and that is necessary for compatibility with lots of things such as SLI which must multiplex frames from multiple cards into the same frame queue. It also massively improves frame pacing. A few years ago, there was a controversy with the disappearance of the “0” setting in NVInspector for Max Prerendered Frames.
You can use tricks to reduce a lot of lag in this lag chain, but VSYNC ON in games can vary humongously between different apps, it’s simply time interval of input read (which necessarily occurs before rendering in most 3D games) versus the pixel hitting the output jack (the point A to B we are limiting scope to for simplicity).
Beam raced frameslices does input read, render AND output in essentially realtime. Just like the original machine did. Faithfully. With it, there can be just be a mere 1 millisecond between an input read and the actual reacted pixels hitting the graphics output. For any game that does continual input reads mid-scanout, the photons of that can actually hit your eyes in subframe time. Like a mid-screen input read for bottom-of-screen pinball flippers.
 ). Now that things are getting closer to working code it does seem like a good time to start up a bounty.
). Now that things are getting closer to working code it does seem like a good time to start up a bounty.